The LeepCast Blog
Stories worth your attention
No hype, no filler — reporting and analysis on AI, software, hardware, and security, written for the people who build things.

Before Multimodal RAG: What I Learned Getting Clean Text Out of Real PDFs
Multimodal RAG gets all the attention, but when I built DocQA I never reached it - I got stuck on the unglamorous prerequisite: pdf.js does not give you clean text, and a naive fragment-join shatters Telugu, Arabic, and CJK into nonsense. Here is the geometry-based extractor and Private-Use-Area filter I actually wrote, and the honest line where a text pipeline stops and multimodal has to start.

Evaluating AI Agents: Score the Trajectory, Not the Last Line
A model eval is one prompt and one grade. An agent eval has to judge a whole run — the tools it called, the dead ends, the recoveries, the cost. Here is a mental model, a worked example, and a scorecard in code that catches the agents that pass by luck.
Constrained Decoding Doesn't Fix Bad Output — It Moves the Failure Somewhere Quieter
Constrained decoding guarantees your JSON parses. That is real, and it is smaller than it sounds. The guarantee is purely structural, so every failure that used to crash loudly at the parser now survives as a well-formed, wrong object. Here is the mental model I use to decide where that trade actually pays off — and the three production edges that bite.

Fine-Tuning, RAG, or Prompting? Diagnose the Failure Mode, Not the Vibe
Most teams pick their LLM lever from a blog post, then spend a quarter discovering they solved the wrong problem. Here's the diagnostic I actually use: read the model's wrong answer like a bug report, classify the failure into one of four buckets, and let the fix fall out — with a worked example, a rough cost model, and the gotchas nobody warns you about.
HNSW in Production: The Vector Index Nobody Tells You How to Operate
Every tutorial explains HNSW as a pretty layered graph and stops there. That leaves out the part that actually bites you: the index is a RAM-resident structure that fights you on deletes, silently drops recall when your embeddings drift, and turns two innocent-looking knobs into your entire latency budget. Here is the operator's mental model, a worked ef-tuning walkthrough, and the decision framework for when to reach for something else.

Model Merging Is a Free Lunch With a Hidden Bill: The Trick and the Caveats
Averaging the weights of two fine-tunes into one model that has both their skills sounds fake, and mostly it works. But the leaderboard-screenshot version of this story stops at the magic and never mentions tokenizer drift, eroded safety, or benchmark leakage masquerading as skill. Here is the trick AND the bill: a mental model, a merge-vs-LoRA-vs-fine-tune decision, and the gotchas that decide whether a merge helps or quietly ships a regression.
Grounding Does Not Kill Hallucinations — It Just Moves Them Somewhere You Can See
Every guide tells you to add RAG and a verifier and call it solved. That advice is half-right in a way that quietly ships bugs. Here is the mental model I use, a support-bot walkthrough where grounding backfires, and a decision table for when NOT to reach for it.

Prompt Caching Is a Byte-Determinism Problem: What I Learned Building a Cache-Stabilizer
Every dynamic token in your system prompt — today's date, a UUID, a session ID — quietly drops your provider cache hit-rate to zero and inflates your bill. Building Headroom's cache layer taught me the fix isn't to rewrite the prompt (I tried, it broke a core invariant and I deleted it) but to keep the hot zone byte-identical.

Red-Teaming LLMs: Stop Counting Jailbreaks, Start Counting Consequences
Most red-teaming advice hands you a taxonomy of attacks and tells you to automate them. That's the least durable part. The real question isn't 'can someone jailbreak the model?' — it's 'if they do, what can it actually reach?' Here's a threat-model-first harness, a worked example from a scanner that reads the open web, and the false-positive trap nobody warns you about.
RLHF vs DPO in Practice: A Field Guide to Preference Tuning (and When It Quietly Goes Wrong)
Most explainers stop at "show the model which answer humans preferred." That is the easy 10%. This is the other 90%: a worked support-bot example, the DPO loss in plain code, a decision framework for RLHF vs DPO vs neither, and the production failure modes — verbosity tax, reference drift, contaminated pairs — that nobody warns you about until your tuned model gets worse.
Agentic RAG, and Why I Deliberately Did Not Build It Into My Document Q&A App
Every explainer tells you to hand retrieval to the model as a tool. When I built DocQA — a Claude-powered doc Q&A app with cached full-document mode, a hand-rolled BM25 fallback, and clickable citations — the more useful lesson was knowing which questions deserve an agentic loop and which are cheaper answered without one. Here is the real baseline, the real cost trade, and the PDF gotchas that actually ate my time.
Voice Agents Are a Latency Budget in Disguise: The Numbers That Decide If Yours Feels Human
Every 'voice agent' tutorial hands you the same STT to LLM to TTS diagram and tells you to 'stream everything.' None of them tell you the actual millisecond budget you're spending, or which line items to cut first. Here is voice as a ledger you have to balance — with a worked turn, a real interrupt loop, and the gotchas that only show up on a real phone line.
Synthetic Data for LLMs: Why Your Yield Rate Matters More Than Your Prompt
Most synthetic-data guides obsess over the generation prompt. The number that actually decides whether your fine-tune works is yield: what fraction survives filtering. Here's a factory mental model, a worked support-classifier example, and a decision table for when synthetic data quietly ruins a model.
Function Calling Isn't Magic: Treat Your LLM Like an Untrusted Intern With a Typewriter
The model never runs your code — it slides a note under the door asking you to. Everything that goes wrong in production agents comes from skipping the clerk who checks that note. A worked refund-bot example, a trade-off table, and the gotchas the quickstart never mentions.

Text-to-SQL's Real Risk Isn't the Query That Fails — It's the One That Silently Lies
Everyone frames text-to-SQL as accuracy vs. safety. But safety is the easy half — a read-only role and a timeout, written once. The hard, under-discussed failure is a query that runs perfectly and returns a confident, wrong number. Here's why that happens, a worked example, and a framework for when to trust it.
LLM-as-a-Judge: The Grader Has Opinions, and One of Them Is About You
Most teams deploy an LLM judge as if it were a ruler. It's more like a smart, slightly lazy intern who agrees with you a little too easily. Here's a mental model, a worked example where the judge is confidently wrong, and a decision table for when to trust it, when to distrust it, and when to not use it at all.

Continuous Batching, Read Through One Number: Average GPU Seat Occupancy
Most explanations stop at 'it's a clever scheduler.' That hides the lever that decides your bill. Here is the mental model I use, a worked before/after on a single GPU, a table for when NOT to reach for it, and the production gotchas static-batching tutorials skip.
Tokenization at the Edges: What a Telugu Voice Clone Taught Me When the Model Kept Dropping My English
The textbook lesson is that non-English text costs more tokens. Building IndicF5 — a local Telugu voice-clone TTS that reads my own tech writing aloud — taught me the harder version: at the edge of a model's vocabulary, "costs more" quietly becomes "silently dropped." Here's how tokenization really works, and the hand-built normalizer I had to write to work around it.

Model Cascades in Production: The Math That Decides If Routing Is Worth It
Everyone tells you to route easy queries to a cheap model and escalate the hard ones. Nobody tells you the escalation rate and verifier cost where that math flips and a cascade starts costing you MORE than just calling the big model. Here is the arithmetic, a worked example, and the three failure modes that quietly eat the savings.
Chunking for RAG, Learned the Hard Way: What I Actually Chose Building DocQA
Chunking silently caps how good retrieval can ever be, and I only understood that after hand-tuning it for DocQA - a vector-DB-free Claude document Q&A app. Here is the general theory plus the exact choices I made: 1600-char chunks, boundary-preferring splits, page-threaded citations, and the pdf.js extraction gotcha that ate most of my time.
Quantization Isn't Compression — It's a Bet on Which Bits Were Bluffing
Everyone explains quantization as 'store the weights in fewer bits.' That framing hides the only decision that matters: which numbers you're allowed to be wrong about. Here's a mental model, a worked 70B-on-one-GPU example, a when-to-use / when-it-breaks table, and the gotchas that bite you in production instead of in the demo.
Speculative Decoding Is a Bet on How Predictable Your Traffic Is
Everyone calls speculative decoding a free lunch. It isn't free - you pre-pay compute against a wager that your next tokens are guessable. Here is the mental model, a worked acceptance-rate calculation, and the production failure modes the docs skip.
Knowledge Distillation Is a Data Problem Wearing a Loss Function's Clothes
Most explainers open with temperature and KL divergence, as if distillation were a clever loss trick. After building generative models where a small student imitates a stronger source, I think the loss is the least interesting part. The real work is choosing what the teacher generates, catching where its confident wrongness gets copied verbatim, and knowing the three failure modes tutorials never mention. Here is the version I wish I had read first.
Mixture of Experts, from a Capacity-Planning Chair: The Router Is Cheap, the VRAM Bill Is Not
Every MoE explainer tells you a 744B model runs like a 40B one. True, and useless when you are sizing a GPU box. Here is the mental model I actually use — one number for latency, a different number for memory — plus a worked capacity calc, a when-to-use table, and the gotchas that bite in production.
Do You Even Need an Embedding Model? A Fine-Tuning Decision Guide (With a RAG App That Shipped Without One)
The internet tells you how to pick and fine-tune an embedding model but skips the prior question: whether you need one. Here is the decision framework, the fine-tuning code, and the story of a document-Q&A app I built that ships real RAG with zero embeddings — a hand-rolled BM25 — plus the production gotchas that bite after you choose.

Running a Vision Model 100% in the Browser: What I Learned Shipping PassportPhotoStudio
Everyone talks about vision-language models as one more field in an API call. I went the other way and ran a real segmentation model client-side — WebGPU with a WASM fallback, int8 quantization to cut the download from ~168MB to ~42MB, and two perf bugs that cost me seconds per frame. Here is what actually happened.

I Gave My Robot Dog Offline AI: Three Neural Nets on a Raspberry Pi 5 CPU
Chinnu, my Telugu-speaking robot dog, can now hear, talk, and see — three neural networks running entirely on a Raspberry Pi 5 CPU, with no GPU, no NPU, and no cloud. Including YOLOv8n object detection at ~24 FPS, and a cache that lets the cloud quietly teach the local model.
Long Context vs RAG Is the Wrong Fight: What I Learned Building a Compression Layer
The million-token debate assumes your only choice is stuff-it-all-in or retrieve-fragments. Building Headroom, a local-first context-compression layer, showed me a third axis the debate ignores: how much of what already landed in your context you should keep paying full price for. Real architecture, a reversible-compression pattern, an 87.6% JSON benchmark, and the cache invariant that cost me a rewrite.
Re-ranking, and When I Deliberately Skipped It: Retrieval Lessons From Building DocQA
Everyone says a cross-encoder re-ranker is RAG's cheapest big win. Building DocQA, a Claude-powered document Q&A app, I skipped it — no embeddings, no vector DB, just size-based mode switching and hand-rolled BM25. Here is what re-ranking actually fixes, why a single-document app doesn't need it, and where the real retrieval-quality wins turned out to be.

Chinnu: I Built an AI Robot Dog That Speaks Telugu
Chinnu is an AI robot dog that sees, talks back in natural Telugu, obeys voice commands, and reacts to a pat on the head. The best part — it understands Telugu commands fully offline, using a tiny model I trained on my own voice.

Reasoning Models: Stop Pricing Them Per Token, Price Them Per Correct Answer
A reasoning model that costs 6x per token but turns a 60% success rate into 95% can be cheaper than the 'cheap' model once you count the retries, the human review, and the wrong answers that ship. Here's the mental model, a worked cost example, a real router, and the production gotchas the docs skip.
What I Learned Building a Cursor-Style AI Coding Panel in ~300 Lines
Everyone talks about AI coding agents like magic. I built a working Claude chat panel into VS Code as one ~300-line extension, and it taught me exactly how thin the demo layer is — and where the genuinely hard part (context and multi-file edits) actually begins.
Prompt Engineering as Spec-Writing: A Working Engineer's Playbook
Stop treating prompts as clever phrasing. Treat them as the loosest, cheapest specification in your stack -- and debug them the way you debug a flaky function. Here's the mental model, a worked before/after, and the failure modes that bite in production.

You're Not Choosing a Vector Database — You're Choosing a Recall Budget
Most vector-DB comparisons argue about brands. The decision that actually bites you in production is quieter: how much search accuracy you're silently trading for speed, and what happens to it the moment you add a filter. Here's a mental model, a worked cost example, and the failure modes the docs skip.

Streaming LLM Responses Is a UX Trick, Not a Speed-Up — Here's Where That Bites You
Everyone tells you to stream token-by-token because it feels fast. True — but streaming quietly turns one atomic HTTP response into a distributed system with partial failures, half-parsed JSON, and cost you can't read until the last chunk. Here's a mental model, a worked before/after, and a table of when NOT to bother.
Semantic Caching Is the Second Cache: What I Learned Cutting an Agent's Token Bill
Everyone reaches for semantic caching to cut LLM costs. Building Headroom, an open-source context-compression proxy, taught me the bigger win for agents is the provider prompt cache -- and the fastest way to lose it is to "helpfully" rewrite your system prompt. A first-hand look at byte-determinism, a mistake I shipped then deleted, and why I detect volatile tokens with parsers instead of regex.
Multi-Agent Orchestration Is a Concurrency Problem Wearing an AI Costume
Everyone draws the same coordinator-and-workers diagram and skips the part that actually breaks: shared state, race conditions, and trust boundaries. Here's what orchestration really costs -- grounded in a real system that fans job evaluations out to N parallel agents.
GraphRAG in Practice: The 'Nodes vs Edges' Test for When Your RAG Needs a Graph
Most GraphRAG advice tells you what a knowledge graph is. This is the decision I actually make before building one: is the question about a thing, or about a path between things? Here's the test, a supply-chain example traced hop by hop, and the four production gotchas that eat the afternoon nobody budgets for.

Guardrails Are a Trust Boundary, Not a Filter: What I Learned Wiring an LLM Into a Job Scanner
Most guardrail advice treats prompt injection as a spam problem you solve with a blocklist. It isn't. It's a trust-boundary problem — the same one that produces SSRF and XSS. Here's the mental model, plus three real gotchas from an agent I built that reads untrusted web pages for a living.
LLM Observability: Sample the Costly, Trace the Weird, Score the Rest
Most LLM observability advice tells you to "log everything." That is how you get a $4,000 tracing bill and a dashboard nobody reads. Here is a sampling-first mental model, a worked incident, and the gotchas that only show up once real traffic hits your spans.

I Built an AI Agent That Doesn't Forget Me (Without Fine-Tuning)
SelfMind wraps Claude in a persistent memory + RAG loop: it decides what's worth remembering after each turn and writes it to SQLite, so a fresh session still knows you. Here's the real architecture, in ~637 lines with one dependency, and the design calls I made instead of fine-tuning.

LoRA Fine-Tuning: What Nobody Tells You Until Your First Run Comes Out as Noise
LoRA made fine-tuning cheap enough for a single GPU, but 'cheap' and 'easy' are different words. Here's a real decision framework for when to fine-tune, plus the unglamorous failure modes I hit fine-tuning a Telugu voice model on my own laptop — including the one where a checkpoint loaded 'successfully' and produced pure static.
Structured Outputs Are a Schema-Design Problem, Not a JSON Problem
Everyone frames structured outputs as "how do I stop the model wrapping JSON in a markdown fence." That is the easy 5%. The hard part is designing a schema that stays honest when the model does not actually know the answer. Here is what changed my mind, using a real agent pipeline I work in.
Context Engineering in Practice: What Building a Token-Compression Layer Taught Me About the Window
Context engineering sounds abstract until you have to ship it. Building Headroom -- a local-first layer that shrinks tool outputs, logs, and RAG chunks by an advertised 60-95% before they reach the model -- turned tidy context-window advice into concrete design calls: reversible compression, a cache you can torch with one byte, and savings you literally cannot measure head-on.
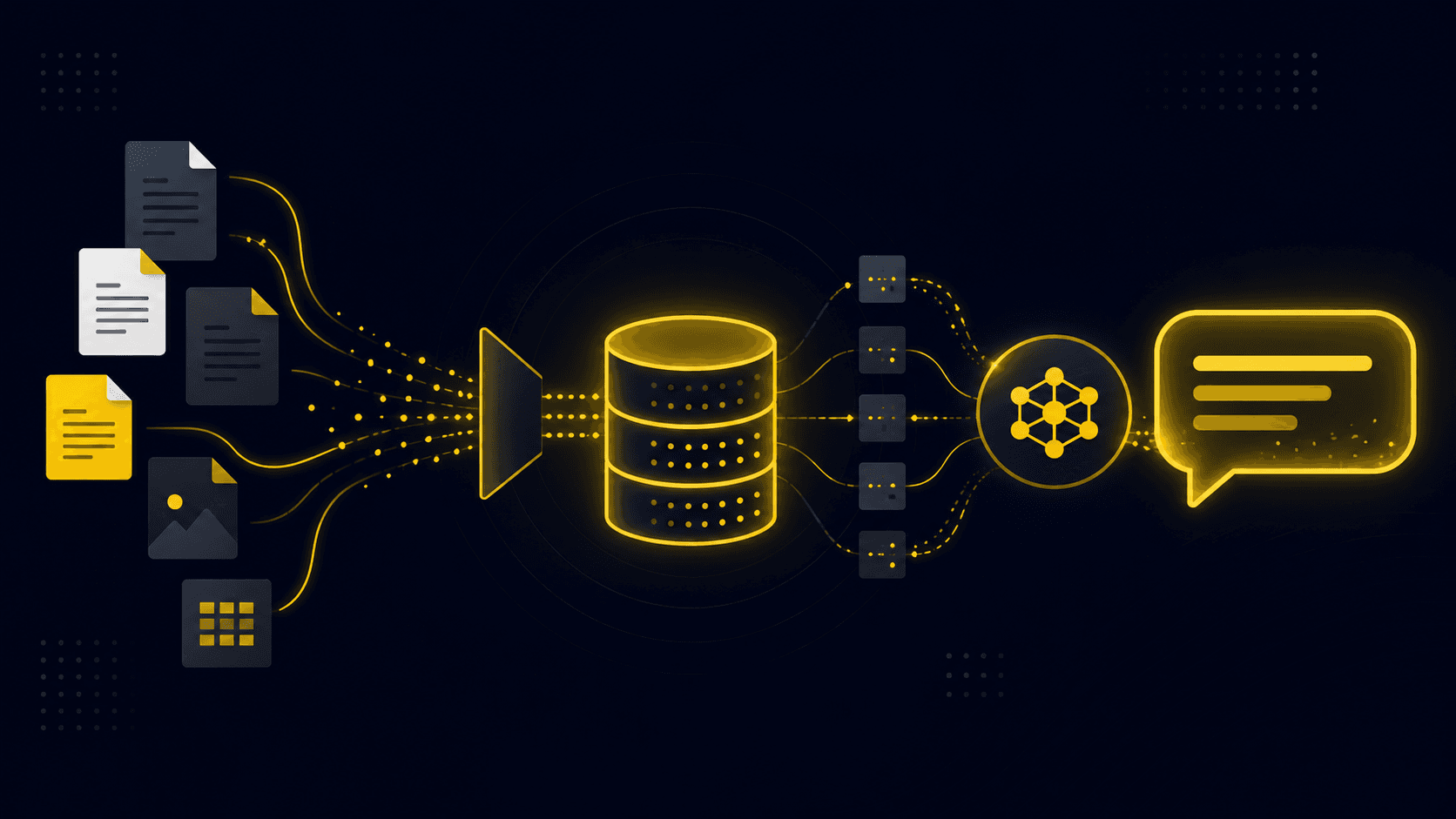
I Built a RAG App With No Vector Database. Here's the Whole Pipeline.
Everyone reaches for a vector DB and embeddings the moment they hear "RAG." I built DocQA — a Claude-powered document Q&A app — on hand-written BM25, a size-based context switch, and a two-block cached prompt. Here's the real architecture, the numbers that are actually config constants (not benchmarks), and the PDF-parsing bug that ate most of the work.

How I Evaluate LLM Apps: Evals From a Cited Document Q&A App (and One I Didn’t Evaluate)
You can't assertEquals a language model. Building DocQA, a Claude RAG app that cites its sources, taught me which failures a unit test still catches, which need real evals -- and why my other project, SelfMind, has none and shouldn't be trusted yet.

Running Models Locally: What Ollama and vLLM Skip, and What I Learned Keeping One Warm on a Mac
Ollama and vLLM make local inference look like two commands. But the interesting part is everything underneath — device selection, CPU fallbacks, keeping the model warm, caching. I built a local Telugu voice-clone TTS on an Apple Silicon Mac (no Ollama, just raw PyTorch and transformers), and it taught me the operational reality those two commands hide.

Model Context Protocol Explained: What I Learned Shipping a Real MCP Server
MCP is USB-C for AI, but the abstract version teaches you nothing. Here's what actually happened when I shipped an MCP server for Headroom, my context-compression tool: why three narrow tools beat one, why I deleted a clever cache trick, and how a reversible compress/retrieve pair made a lossy transform safe to expose to an agent.
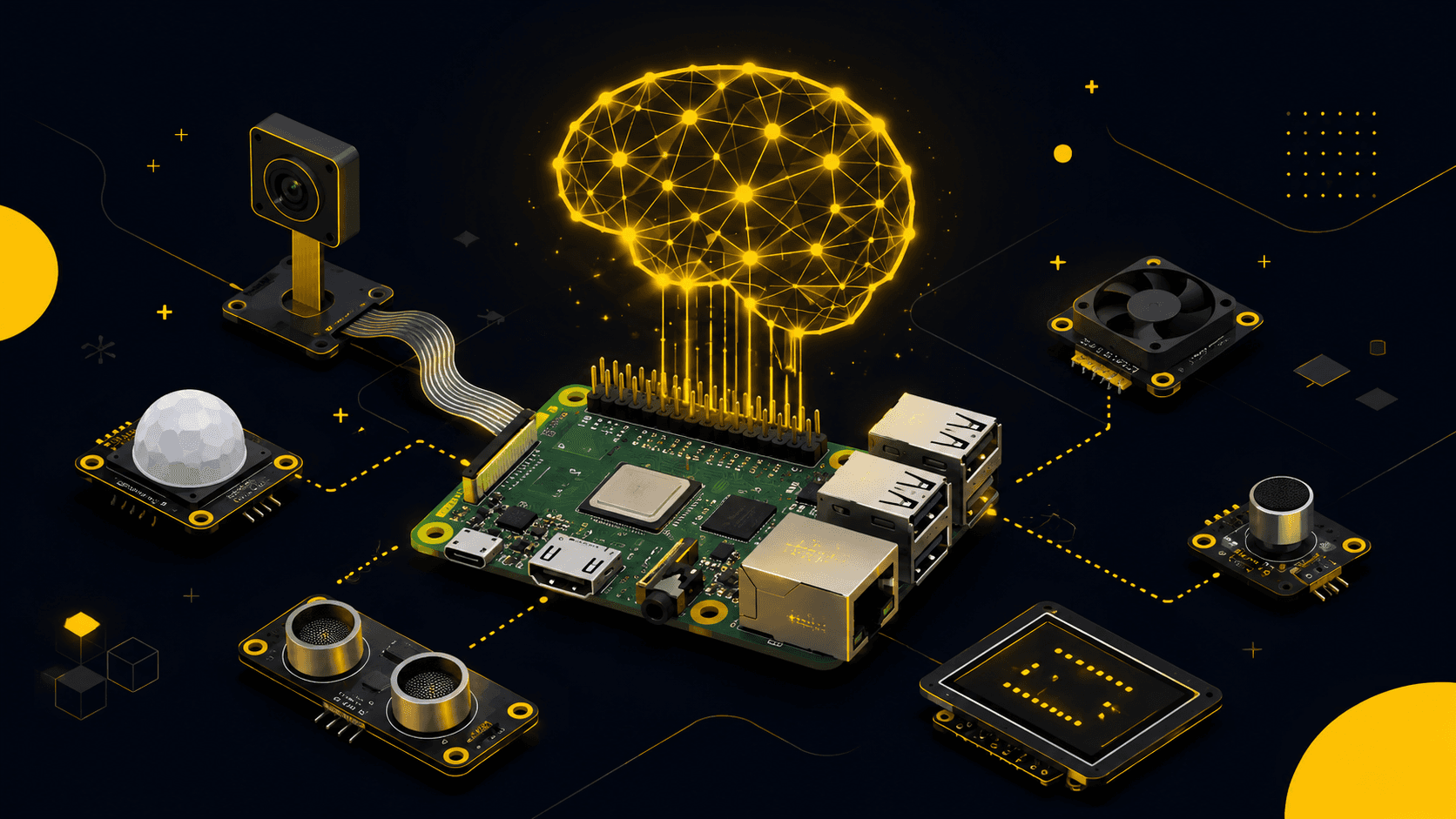
The Raspberry Pi AI Project Nobody Lists: An LLM-Controlled Network Throttle
Most "AI on a Pi" projects try to run a model on the board. I built the opposite: a Pi that shapes network traffic with Linux tc, while Claude turns "add 300ms lag to the PS5" into one structured tool-call. Here's the real architecture, the code, and the physical limits that make it an honest first project.

Deploying LLM Apps on GKE: The Bill Is the Design Document
Most GKE-for-LLM guides hand you manifests. None of them tell you the one number that should drive every decision: cost per thousand tokens served. Here's a mental model that starts from the bill and works backward — including the two mistakes that turn a $300/month deploy into a $4,000 one.

The AI Gateway You Already Built By Accident (And How to Design It On Purpose)
An AI gateway is not really an API gateway with a new logo. It is a money meter and a blast-radius controller for language models. Here is a mental model, a worked routing example, and the failure modes that only show up at 2am -- including the timeout trap and semantic-cache poisoning the docs gloss over.

The Refund Agent That Can't Be Talked Into a Refund: AI Agents in Java + Spring Boot
The agent tutorials all assume a green-field Python service. But the orders, policies, and money your agent must touch already run on the JVM. Here's the real shape of a Spring AI agent — a worked refund example where the model asks and your code decides, plus the production failure modes the quickstart skips.

STAR+R: The Interview-Prep Format I Built Into My Job-Search Tool
When I built career-ops, my open-source job-search pipeline, the interview module became the piece I trust most. The reason is one extra column -- Reflection -- and a story bank that reuses your best answers across every interview.

What Actually Makes an AI Resume Pass ATS: Notes From Building the Normalizer
"AI resume" usually means "stuff it with keywords." The real work is duller and more interesting: a Unicode-to-ASCII pass that kills em-dashes and smart quotes before a parser mangles them, a banned-cliche list, and a step that mimics your own writing. Here is what I learned building all three into an open-source job-search tool.

What a Genuinely Good AI Job Tool Looks Like Under the Hood
Most 'AI job tools' are a prompt in a trench coat. I read the source of an open-source one that isn't -- a zero-token scanner you extend by dropping in one file, a fit score that tells you NOT to apply, and a ghost-job detector that grades a posting's legitimacy separately from its fit.
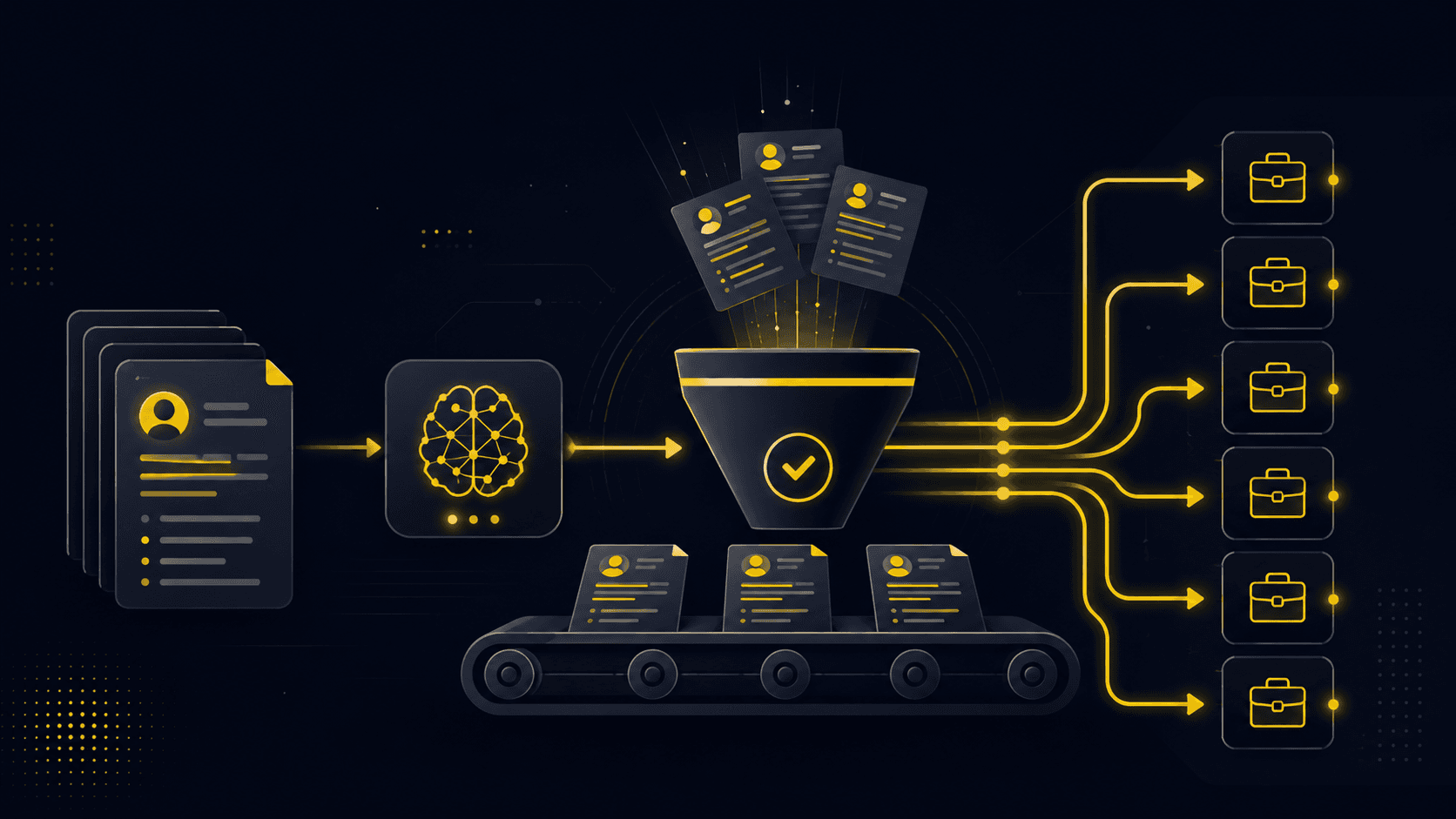
I Built an AI Job-Hunt Pipeline That Rejects Almost Every Job
career-ops is an open-source pipeline I built to scan, score and tailor applications across hundreds of postings. The real engineering wasn't the AI -- it was a zero-token scanner, an SSRF allowlist, and one rule that stops it blacklisting live jobs.

The agents are here — so I built one in 300 lines to see how thin it really is
I built mini-cursor, a Cursor-style AI panel for VS Code, in one source file and ~300 lines. The streaming plumbing was trivial; the 12K-char context cap and the line-number problem showed me where the real work — RAG and safe multi-file edits — actually begins.

Rust-based JS tooling: adopt it for the consolidation, not the speed
The 10x benchmark is real and mostly beside the point. A worked lint-and-format swap, the three compatibility seams that actually break in production, and a swap-now / wait / leave-it framework for deciding which native tools to trust today.

On-device AI, from the inside: I ran a voice-clone model on my Mac's silicon
NPUs and Apple's MPS backend promise private, local AI. Here's what it actually cost me — ~5x-slower-than-real-time synthesis, a mandatory lock, CPU fallbacks, and a weight-loading bug that turns a model into pure noise — building an offline Telugu voice clone.
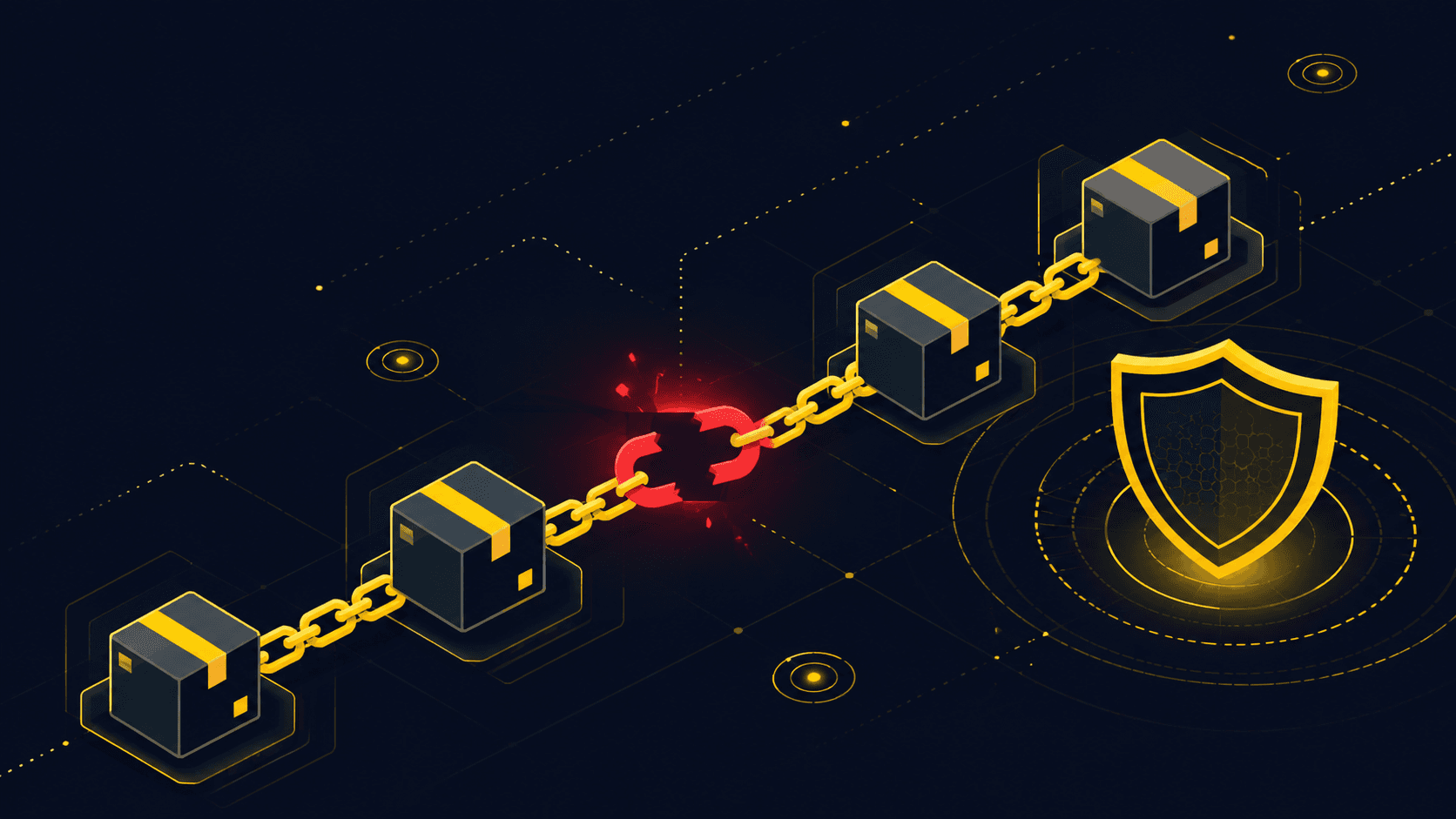
Stop Auditing Dependencies. Start Containing Them.
Reading every package is a losing game. The teams that survive supply chain attacks treat install-time as a privilege boundary and score every control by blast radius, not by how thorough it feels.